 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Degradation-Aware 3D Gaussian Splatting for Realistic Underwater Scene Reconstruction
Apr 26, 2026Reconstructing realistic underwater scenes from underwater video remains a meaningful yet challenging task in the multimedia domain. The inherent spatiotemporal degradations in underwater imaging, including caustics, flickering, attenuation, and backscattering, frequently result in inaccurate geometry and appearance in existing 3D reconstruction methods. While a few recent works have explored underwater degradation-aware reconstruction, they often address either spatial or temporal degradation alone, falling short in more real-world underwater scenarios where both types of degradation occur. We propose MarineSTD-GS, a novel 3D Gaussian Splatting-based framework that explicitly models both temporal and spatial degradations for realistic underwater scene reconstruction. Specifically, we introduce two paired Gaussian primitives: Intrinsic Gaussians represent the true scene, while Degraded Gaussians render the degraded observations. The color of each Degraded Gaussian is physically derived from its paired Intrinsic Gaussian via a Spatiotemporal Degradation Modeling (SDM) module, enabling self-supervised disentanglement of realistic appearance from degraded images. To ensure stable training and accurate geometry, we further propose a Depth-Guided Geometry Loss and a Multi-Stage Optimization strategy. We also construct a simulated benchmark with diverse spatial and temporal degradations and ground-truth appearances for comprehensive evaluation. Experiments on both simulated and real-world datasets show that MarineSTD-GS robustly handles spatiotemporal degradations and outperforms existing methods in novel view synthesis with realistic, water-free scene appearances.
* 12 pages, 10 figures, 6 tables. Author version of the paper published in Proceedings of ACM Multimedia 2025
RankUp: Towards High-rank Representations for Large Scale Advertising Recommender Systems
Apr 21, 2026The scaling laws for recommender systems have been increasingly validated, where MetaFormer-based architectures consistently benefit from increased model depth, hidden dimensionality, and user behavior sequence length. However, whether representation capacity scales proportionally with parameter growth remains largely unexplored. Prior studies on RankMixer reveal that the effective rank of token representations exhibits a damped oscillatory trajectory across layers, failing to increase consistently with depth and even degrading in deeper layers. Motivated by this observation, we propose \textbf{RankUp}, an architecture designed to mitigate representation collapse and enhance expressive capacity through randomized permutation splitting over sparse features, a multi-embedding paradigm, global token integration, crossed pretrained embedding tokens and task-specific token decoupling. RankUp has been fully deployed in large-scale production across Weixin Video Accounts, Official Accounts and Moments, yielding GMV improvements of 3.41\%, 4.81\% and 2.21\%, respectively.
Adversarial Arena: Crowdsourcing Data Generation through Interactive Competition
Apr 20, 2026Post-training Large Language Models requires diverse, high-quality data which is rare and costly to obtain, especially in low resource domains and for multi-turn conversations. Common solutions are crowdsourcing or synthetic generation, but both often yield low-quality or low-diversity data. We introduce Adversarial Arena for building high quality conversational datasets by framing data generation as an adversarial task: attackers create prompts, and defenders generate responses. This interactive competition between multiple teams naturally produces diverse and complex data. We validated this approach by conducting a competition with 10 academic teams from top US and European universities, each building attacker or defender bots. The competition, focused on safety alignment of LLMs in cybersecurity, generated 19,683 multi-turn conversations. Fine-tuning an open-source model on this dataset produced an 18.47% improvement in secure code generation on CyberSecEval-Instruct and 29.42% improvement on CyberSecEval-MITRE.
Amazon Nova AI Challenge -- Trusted AI: Advancing secure, AI-assisted software development
Aug 13, 2025AI systems for software development are rapidly gaining prominence, yet significant challenges remain in ensuring their safety. To address this, Amazon launched the Trusted AI track of the Amazon Nova AI Challenge, a global competition among 10 university teams to drive advances in secure AI. In the challenge, five teams focus on developing automated red teaming bots, while the other five create safe AI assistants. This challenge provides teams with a unique platform to evaluate automated red-teaming and safety alignment methods through head-to-head adversarial tournaments where red teams have multi-turn conversations with the competing AI coding assistants to test their safety alignment. Along with this, the challenge provides teams with a feed of high quality annotated data to fuel iterative improvement. Throughout the challenge, teams developed state-of-the-art techniques, introducing novel approaches in reasoning-based safety alignment, robust model guardrails, multi-turn jail-breaking, and efficient probing of large language models (LLMs). To support these efforts, the Amazon Nova AI Challenge team made substantial scientific and engineering investments, including building a custom baseline coding specialist model for the challenge from scratch, developing a tournament orchestration service, and creating an evaluation harness. This paper outlines the advancements made by university teams and the Amazon Nova AI Challenge team in addressing the safety challenges of AI for software development, highlighting this collaborative effort to raise the bar for AI safety.
Topology-Aware 3D Gaussian Splatting: Leveraging Persistent Homology for Optimized Structural Integrity
Dec 21, 2024Gaussian Splatting (GS) has emerged as a crucial technique for representing discrete volumetric radiance fields. It leverages unique parametrization to mitigate computational demands in scene optimization. This work introduces Topology-Aware 3D Gaussian Splatting (Topology-GS), which addresses two key limitations in current approaches: compromised pixel-level structural integrity due to incomplete initial geometric coverage, and inadequate feature-level integrity from insufficient topological constraints during optimization. To overcome these limitations, Topology-GS incorporates a novel interpolation strategy, Local Persistent Voronoi Interpolation (LPVI), and a topology-focused regularization term based on persistent barcodes, named PersLoss. LPVI utilizes persistent homology to guide adaptive interpolation, enhancing point coverage in low-curvature areas while preserving topological structure. PersLoss aligns the visual perceptual similarity of rendered images with ground truth by constraining distances between their topological features. Comprehensive experiments on three novel-view synthesis benchmarks demonstrate that Topology-GS outperforms existing methods in terms of PSNR, SSIM, and LPIPS metrics, while maintaining efficient memory usage. This study pioneers the integration of topology with 3D-GS, laying the groundwork for future research in this area.
Aquatic-GS: A Hybrid 3D Representation for Underwater Scenes
Oct 31, 2024



Representing underwater 3D scenes is a valuable yet complex task, as attenuation and scattering effects during underwater imaging significantly couple the information of the objects and the water. This coupling presents a significant challenge for existing methods in effectively representing both the objects and the water medium simultaneously. To address this challenge, we propose Aquatic-GS, a hybrid 3D representation approach for underwater scenes that effectively represents both the objects and the water medium. Specifically, we construct a Neural Water Field (NWF) to implicitly model the water parameters, while extending the latest 3D Gaussian Splatting (3DGS) to model the objects explicitly. Both components are integrated through a physics-based underwater image formation model to represent complex underwater scenes. Moreover, to construct more precise scene geometry and details, we design a Depth-Guided Optimization (DGO) mechanism that uses a pseudo-depth map as auxiliary guidance. After optimization, Aquatic-GS enables the rendering of novel underwater viewpoints and supports restoring the true appearance of underwater scenes, as if the water medium were absent. Extensive experiments on both simulated and real-world datasets demonstrate that Aquatic-GS surpasses state-of-the-art underwater 3D representation methods, achieving better rendering quality and real-time rendering performance with a 410x increase in speed. Furthermore, regarding underwater image restoration, Aquatic-GS outperforms representative dewatering methods in color correction, detail recovery, and stability. Our models, code, and datasets can be accessed at https://aquaticgs.github.io.
STGIN: Spatial-Temporal Graph Interaction Network for Large-scale POI Recommendation
Sep 05, 2023



In Location-Based Services, Point-Of-Interest(POI) recommendation plays a crucial role in both user experience and business opportunities. Graph neural networks have been proven effective in providing personalized POI recommendation services. However, there are still two critical challenges. First, existing graph models attempt to capture users' diversified interests through a unified graph, which limits their ability to express interests in various spatial-temporal contexts. Second, the efficiency limitations of graph construction and graph sampling in large-scale systems make it difficult to adapt quickly to new real-time interests. To tackle the above challenges, we propose a novel Spatial-Temporal Graph Interaction Network. Specifically, we construct subgraphs of spatial, temporal, spatial-temporal, and global views respectively to precisely characterize the user's interests in various contexts. In addition, we design an industry-friendly framework to track the user's latest interests. Extensive experiments on the real-world dataset show that our method outperforms state-of-the-art models. This work has been successfully deployed in a large e-commerce platform, delivering a 1.1% CTR and 6.3% RPM improvement.
Alexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Deep Efficient End-to-end Reconstruction (DEER) Network for Low-dose Few-view Breast CT from Projection Data
Dec 16, 2019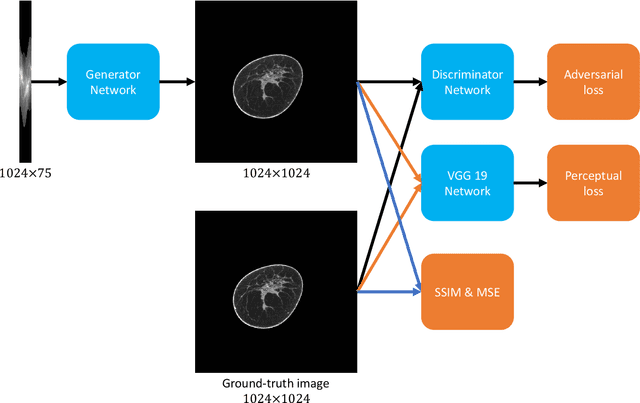
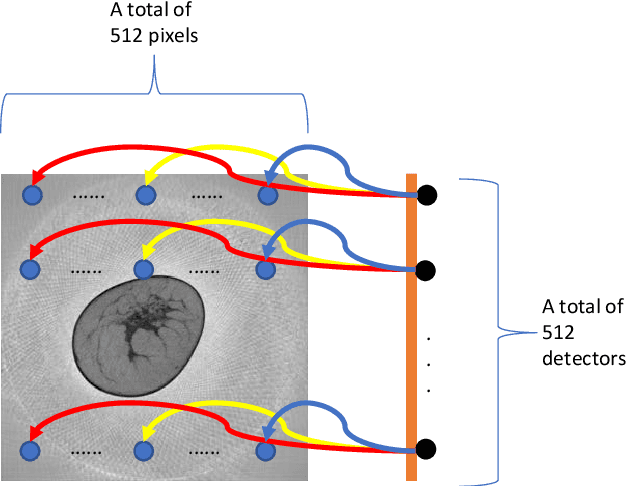
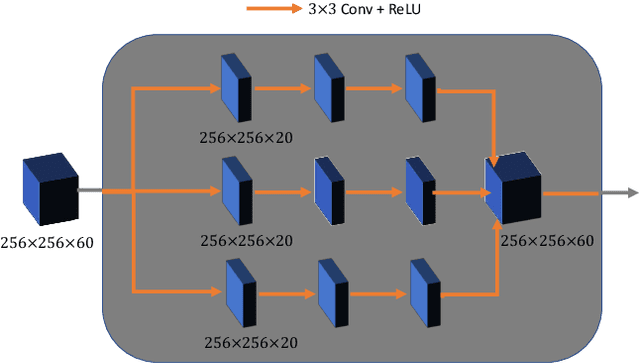
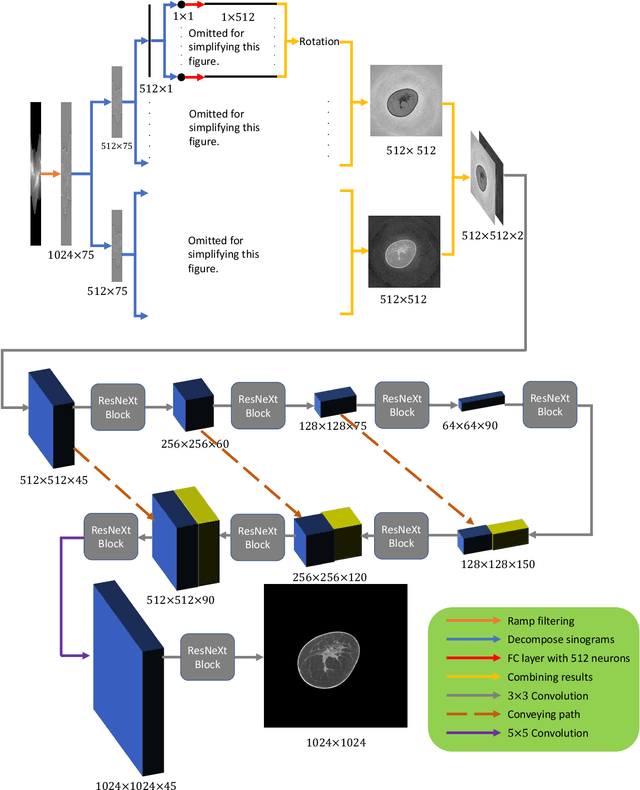
Breast CT provides image volumes with isotropic resolution in high contrast, enabling detection of calcification (down to a few hundred microns in size) and subtle density differences. Since breast is sensitive to x-ray radiation, dose reduction of breast CT is an important topic, and for this purpose low-dose few-view scanning is a main approach. In this article, we propose a Deep Efficient End-to-end Reconstruction (DEER) network for low-dose few-view breast CT. The major merits of our network include high dose efficiency, excellent image quality, and low model complexity. By the design, the proposed network can learn the reconstruction process in terms of as less as O(N) parameters, where N is the size of an image to be reconstructed, which represents orders of magnitude improvements relative to the state-of-the-art deep-learning based reconstruction methods that map projection data to tomographic images directly. As a result, our method does not require expensive GPUs to train and run. Also, validated on a cone-beam breast CT dataset prepared by Koning Corporation on a commercial scanner, our method demonstrates competitive performance over the state-of-the-art reconstruction networks in terms of image quality.
Deep-learning-based Breast CT for Radiation Dose Reduction
Sep 25, 2019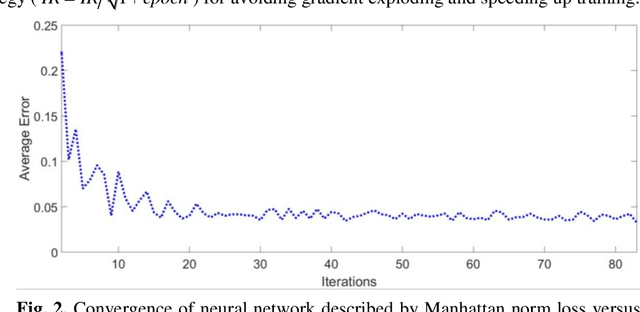
Cone-beam breast computed tomography (CT) provides true 3D breast images with isotropic resolution and high-contrast information, detecting calcifications as small as a few hundred microns and revealing subtle tissue differences. However, breast is highly sensitive to x-ray radiation. It is critically important for healthcare to reduce radiation dose. Few-view cone-beam CT only uses a fraction of x-ray projection data acquired by standard cone-beam breast CT, enabling significant reduction of the radiation dose. However, insufficient sampling data would cause severe streak artifacts in CT images reconstructed using conventional methods. In this study, we propose a deep-learning-based method to establish a residual neural network model for the image reconstruction, which is applied for few-view breast CT to produce high quality breast CT images. We respectively evaluate the deep-learning-based image reconstruction using one third and one quarter of x-ray projection views of the standard cone-beam breast CT. Based on clinical breast imaging dataset, we perform a supervised learning to train the neural network from few-view CT images to corresponding full-view CT images. Experimental results show that the deep learning-based image reconstruction method allows few-view breast CT to achieve a radiation dose <6 mGy per cone-beam CT scan, which is a threshold set by FDA for mammographic screening.